NanoGPT
Published:
This is a LLM project in Tencent.
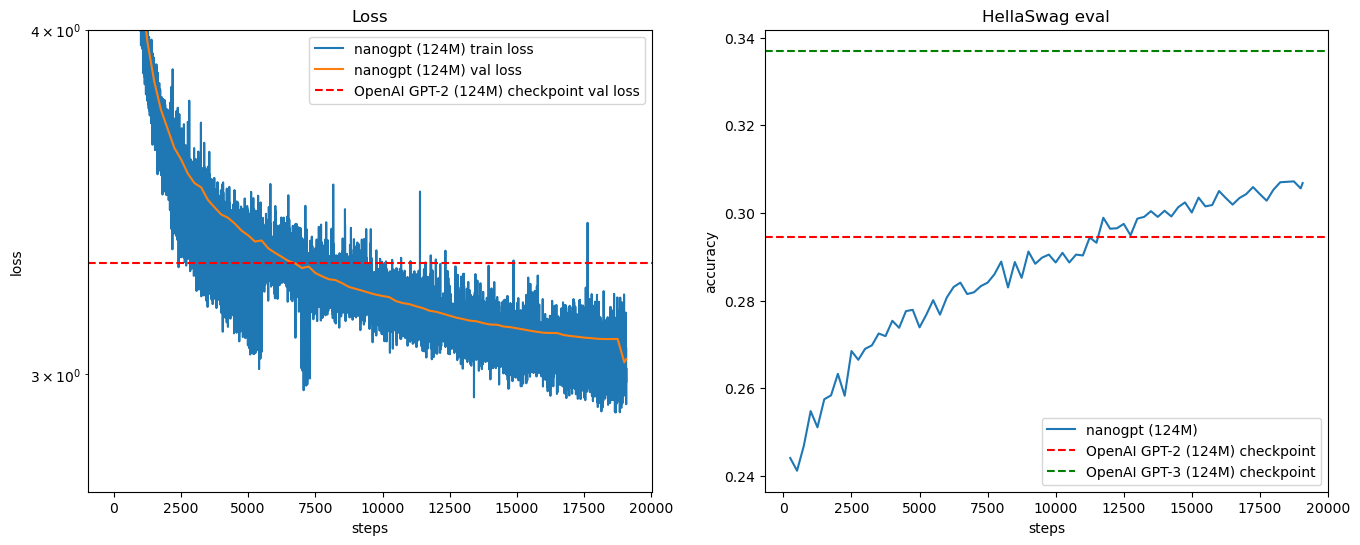
I rebuilt the 124M GPT-2 model using the same tokenizer as OpenAI. I incorporated distributed data parallel (DDP), gradient accumulation, and various other training techniques to accelerate training and optimize it for the hyperparameters of GPT-2 and GPT-3. As a result, the validation accuracy achieved on the well-known HellaSwag validation dataset was 0.31, which is an improvement over the 0.29 achieved by the OpenAI 124M GPT-2.
Here is the Github Repo.
Here is the inference of my nanoGPT:
> Hello, I'm Ako, and I think I'm not a good candidate for our next school vacation. I was born in Norway, and I
> Hello, I'm Ako, so we were at the start of a small event because I had to start writing my first and perhaps a longer paper
> Hello, I'm Ako, and my mother is Aksu, and I'm happy she's got the money. Can my dad still be
> Hello, I'm Ako, and in the beginning I was a little bit shaky on this problem. After all, it was so important.<|endoftext|>
> Hello, I'm Ako, so a little bit of a mess now. I'll say it again, it's pretty nasty. I've started
Architecture
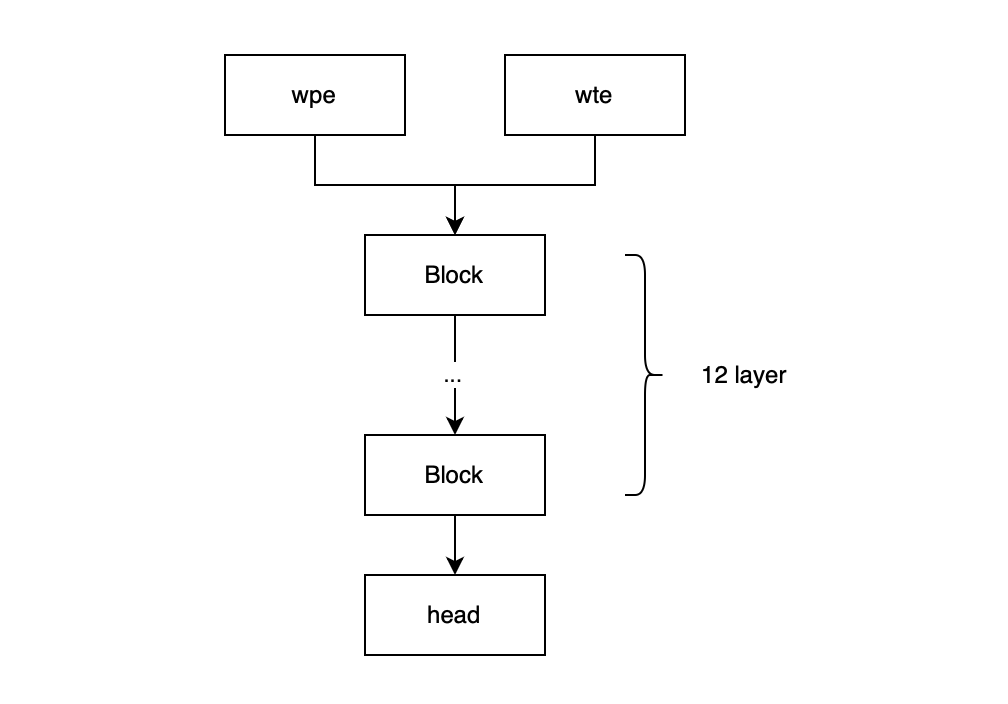
Our Model architecture is almost the same as GPT-2.
The GPT model is decoder model, which means that it composites only embedding layer and decoder.
Here is the graph:
 |  |
Components
0. Tokenizer
Regarding the Tokenizer, we utilize the renowned OpenAI tiktoken, which employs the Bytes Pair Encoding (BPE) method. This approach offers several advantages:
- It is reversible and lossless.
- It effectively handles out-of-vocabulary words.
- It allows the model to recognize common subwords.
Given these benefits, it is clear why BPE is the chosen method in OpenAI, and I have adopted it as well.
| Here is my version of Bytes Pair Encoding, called minibpe |
1. Embedded Layer
The embedded layer contains two parts, the first part is the word token embedding(wte) and word position embedding(wpe).
- The wte represents the vocabulary tokens. Each token is mapped into a high dimension space and this embedding will be trainable during the backpropagation to grasp the meaning of each word.
- The wpe encodes the position of each token in the input sequence. This encoding helps the model understand the sequence of the words.
The final embedding will be the sum of wpe and wte.
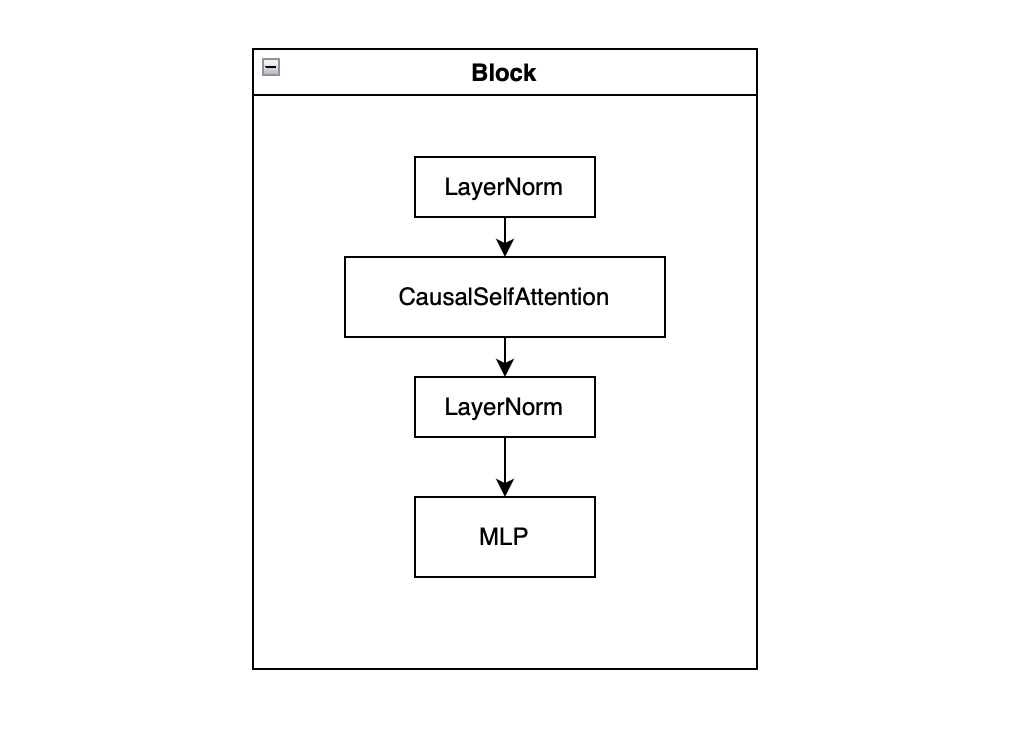
2. Building Block – Self Attention + MLP
The building block contains three parts:
- LayerNorm
- It normalizes the inputs across the features for each individual data point, stablizing the learning process by reducing the the internal covariate shift.
- CausalSelfAttention
- The causal self attention mechanism is the customized version of self-attention which encures the attention mechanism is causal. Each position can only attend to all position before it.
- MLP(Multi-Layer Perceptron)
- structure: Linear + Gelu + Linear
- The MLP processes this combined information captured by the self attention layer to produce more complex features and representations.
- The MLP also uses the dimension expansion and reduction to allow the model learn high dimension interaction.
3. Head Layer
The head layer is a linear layer mapping to the vocab_size.
Training
I train our nanoGPT at two RTX4090 with edu_fineweb10B dataset using several training techniques to optimize the process.
1. Distributed Data Parallel (DDP)
- Two RTX 4090 working in parallel
- Adapt the
bfloat16to reduce the memory usage in the GPU.2. Gradient Accumulation
- To fit the batch size in the OpenAI GPT-2 training, I utilize the gradient accumulation.
3. Cosine Annealing Learning Rate
- Followed the OpenAI GPT-2 training, I adapt to the Cosine Anneling Learning rate in the training process with the gradient cut-off to avoid gradient explosion.
Results
- The training loss and validation loss are as follows, with the comparison to the OpanAI GPT-2
- I use the famous HellaSwag validation dataset to validate both nano-Gpt and GPT-2.